面向互联网信息的舆情检测与预警系统
面向互联网信息的舆情检测与预警系统
目录
环境搭建
配置过程
- 导入项目到idea中: File->open->选中pom.xml->open as project
- IDEA安装lombok插件
- 运行BackendApplication
- 浏览器打开http://localhost:8080/swagger-ui.html 查看接口
获取远程develop分支
- .git中config文件fetch修改为 fetch = +refs/heads/:refs/remotes/origin/
- 右下角刷新、选择分支
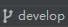
项目组件介绍
缓存机制
- 返回的对象需要实现Serializable接口
- 返回的方法添加@Cacheable(cacheNames = “MESSAGE”, keyGenerator = “DEFAULT”)注解
- 默认的缓存过期时间为一小时
定时任务
定时执行某些接口
为了保证接口的数据被成功缓存,不能直接调用controller中的方法,而应该使用restTemplate的方式进行调用
定时任务采用 接口名称 + cron表达式进行设置
cron表达式用来规定执行的时间,具体用法可见https://www.cnblogs.com/yanghj010/p/10875151.html \
可以使用在线cron表达式生成器对执行时间进行配置,生成器链接:
https://cron.qqe2.com/
性能指标与参数调整
Redis单机性能测试
1 | [dx@IPIR-dx ~]$ redis-benchmark -t get -c 100 -n 1000000 |
负载测试
测试工具 :jemeter
测试规模 :
- 小测试 - 1000用户,每人发送20次,共2万个请求,
- 中测试 - 5000用户,每人发送20次,共10万个请求
- 大测试:10000用户,每人发送20次,共20万个请求
测试持续时间 : 60s, 到时之后将自动停止发送请求,但可能有未执行完的请求会继续排队直至执行完成。
测试接口:message/countMessages
测试环境:i5-6300hq, jvm heap大小为3.53gb
tomcat默认配置:
1 | tomcat: |
| 测试配置 | 请求数量 | 吞吐量/s | 最小返回耗时(ms) | 最大耗时 | 平均耗时 | 错误率 | 接收速率 |
|---|---|---|---|---|---|---|---|
| 无redis | 1790 | 6.2 | 4998 | 123975 | 70637 | 68.32% | 1.59kb/s |
| 单redis-小测试 | 20000 | 2035 | 5 | 3561 | 449 | 0.00% | 443kb/s |
| 单redis-大测试 | 198674 | 2465 | 1 | 3497 | 481 | 1.5% | 1519kb/s |
在单redis-大测试中,出现的异常为HttpHostConnectException。Connect to localhost:8080 failed: Connection refused: connect。这是tomcat可以容纳的同时链接数太少造成的。接下来更新tomcat的配置,将max-connection调为20000;
tomcat配置更新后测试【默认带有redis缓存功能】
tomcat中配置:
1 | tomcat: |
| 测试配置 | 请求数量 | 吞吐量/s | 最小返回耗时(ms) | 最大耗时 | 平均耗时 | 错误率 | 接收速率 |
|---|---|---|---|---|---|---|---|
| tomcat默认-大测试-local | 198674 | 2465 | 1 | 3497 | 481 | 1.5% | 1519kb/s |
| tomcat中-大测试-local | 200000 | 2492 | 3 | 7850 | 1264 | 0.00% | 542kb/s |
在单redis-大测试中,出现的异常HttpHostConnectException在tomcat中-大测试-local中并没有出现,因此可以断定增加tomcat配置可以增加连接的数目,8092的默认数目不够10000的需求,因此出现了异常。
server测试
之前的测试程序和springboot程序运行在同一台机器上,主要是为了消除网络时延对于测试的影响。但是这种情况下,两个程序会争夺系统资源,可能无法将测试结果准确表现出来。因此基于tomcat中配置,在服务器上用docker搭建了测试环境。
测试环境:Intel(R) Xeon(R) CPU E5-2620 v2 @ 2.10GHz。jvm堆大小为8g。
jmeter设置:
1 | Number of Threads: 1000 |
| 测试配置 | 请求数量 | 吞吐量/s | 最小返回耗时(ms) | 最大耗时 | 平均耗时 | 错误率 | 接收速率 |
|---|---|---|---|---|---|---|---|
| 单redis-小测试 | 20000 | 2035 | 5 | 3561 | 449 | 0.00% | 443kb/s |
| tomcat中-小测试-server | 20000 | 311 | 3 | 5998 | 814 | 0.00% | 67.78kb/s |
| tomcat中-中测试-server | 100000 | 818.2 | 5 | 31532 | 4924 | 2.22% | 218.90 |
tomcat中-中测试-server出现了错误。全部为java.net.SocketException,Non HTTP response message: Connection reset,主要问题在于网络。
本地测试和server测试吞吐量对比:
本地测试吞吐量更高,而且由于网络带来的时延,平均耗时约为server的一半。接收速率也高一些。
server测试中的问题
Non HTTP response code: java.net.BindException,Non HTTP response message: Address already in use: connect
ephemeral TCP ports使用量到达了上限,通过增加ephemeral ports的最大数量解决。方案链接
Non HTTP response code: java.net.SocketException,Non HTTP response message: Connection reset
Non HTTP response code: java.net.SocketTimeoutException,Non HTTP response message: Read timed out
Non HTTP response code: org.apache.http.conn.HttpHostConnectException,Non HTTP response message: Connect to 192.168.55.215:8080 [/192.168.55.215] failed: Connection timed out: connect
Non HTTP response code: java.net.SocketException,Non HTTP response message: Software caused connection abort: connect
If your Jmeter is eating all resources will your application will get anything (Simple answer is NO) Thus application will go down and you will start getting timeout errors or socket exceptions.
If you have jmeter and application on diff machines then still 10000 users in 1 second is very high load for a normal application and it is obvious that you will face such errors. Try running test with realistic load that is expected for your application with given hw. Maybe 100 users in 1 second and gradually increase them to expected value.
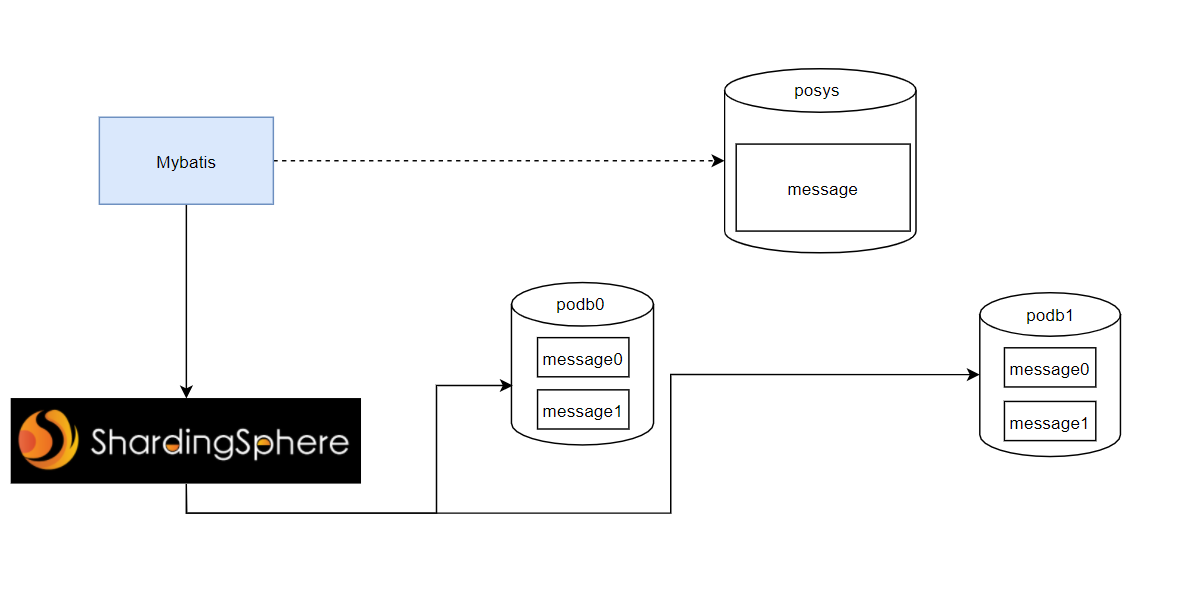
查询优化-分库分表
打开慢查询log, 将慢查询记录阈值设置为5秒。
1 | -- show variables like '%slow%'; |
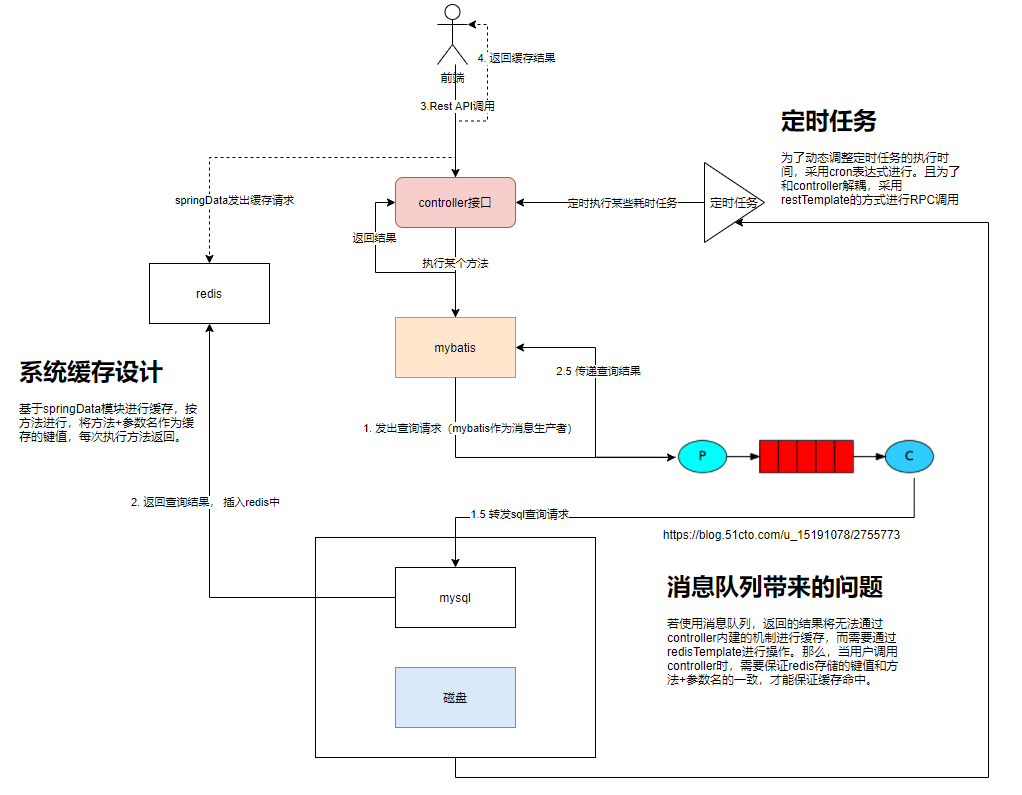
未分库分表迁移到分库分表的方法
在分库上配置适用于mybatis的sharding-jdbc方案。
现在需要将旧库的数据迁移到新库上。主要的方案有停机迁移和非停机迁移两种。为了能在迁移的过程中不影响原数据库的使用,采用双写迁移方法。
方案1 使用ResourceDatabasePopulator进行迁移
首先使用mysqldump将原库中的数据导出为sql脚本格式,然后利用Springboot自带的ResourceDatabasePopulator将sql脚本导入。这里导出的sql脚本大小为4.7GB。
1 |
|
在内存大小为16g的电脑上启动Springboot程序,报错为Failed to execute database script; nested exception is java.lang.OutOfMemoryError : heap,堆内存溢出了。然后试图将堆内存调大,发现还是会出现内存溢出异常——系统内存大小无法满足需要分配的堆内存大小。
方案2 从旧库读取,然后插入新库中
根据mysql开发文档中查询的优化,在插入语句中级联多条记录会增加查询的速度。插入一条语句时需要的时间主要由以下因素决定,后面的数字代表耗费的时间所占的比例。
- Connecting: (3)
- Sending query to server: (2)
- Parsing query: (2)
- Inserting row: (1 × size of row)
- Inserting indexes: (1 × number of indexes)
- Closing: (1)
因此,在一条语句中包含更多条数据可以节省建立连接、解析语句、关闭连接的时间。同时,在新库中将索引暂时关闭,也是有益于数据插入的快速进行的。
不同数据量测试5次,结果如下:
单独插入50000条数据平均耗时:233748ms
批量插入50000条数据平均耗时:2590ms
对比:效率差50倍
单独插入10000条数据平均耗时:22036ms
批量插入10000条数据平均耗时:3330ms
对比:效率差6倍
单独插入1000条数据平均耗时:3122ms
批量插入1000条数据平均耗时:374ms
对比:效率差8倍
其实最快的方式是从文本中直接加载表,这比INSERT语句快20多倍。但是由于这里使用了分表策略,加载时需要考虑数据的哈希定位库表的问题,因此只能选择语句插入的方式。

首先在数据库中记录counter, 保存下一次迁移时的起始id和终止id, 如上图所示。然后主要的工作分为三部分:
- 从旧库中批量读取,从起始id依次读到终止id。
- 向新库中批量插入。
- 递归调用当前函数,进行下一批数据的迁移。
1 | public void migrate(){ |
在插入时不断监看log,如果发生错误应及时修正。
分库分表前后接口耗时测试
| countMessages(index) | getKeywordCount | |
|---|---|---|
| 单库单表 | 26708 | 45476(ALL) |
| 双库四表 | 9513.6(单表4.297) | 15263(单表5827)(ALL) |
| 单库单表+索引 | — | 2049(index) |
| 双库四表+索引 | — | 2395(单表1339)(index) |
利用EXPLAIN来查看上述两条语句的执行计划,并在标题栏中标注出来。ALL、index、range、 ref、eq_ref、const、system、NULL(从左到右,性能从差到好)。
分库效果小结:通过分库可以减少需要扫描全部索引的时间,因此countMessages分库分表执行时间比原来快很多。在getKeywordCount测试中,由于归并需要时间,因此在有索引的情况下,虽然单个小表查询时间比原来少,但是得到汇总结果的时间会多于单表下的查询时间。
分库分表带来的复杂性
跨库关联查询
有几种方案可以解决:
- 字段冗余:把需要关联的字段放入主表中,避免 join 操作;
- 数据抽象:通过ETL等将数据汇合聚集,生成新的表;
- 全局表:比如一些基础表可以在每个数据库中都放一份;
- 应用层组装:将基础数据查出来,通过应用程序计算组装;
分布式事务
单数据库可以用本地事务搞定,使用多数据库就只能通过分布式事务解决了。
常用解决方案有:基于可靠消息(MQ)的解决方案、两阶段事务提交、柔性事务等。
Sharding-jdbc中本地事务完全支持非跨库事务:例如仅分表,或分库但是路由的结果在单库中。同时完全支持因逻辑异常导致的跨库事务。例如:同一事务中,跨两个库更新。更新完毕后,抛出空指针,则两个库的内容都能回滚。但是不支持因网络、硬件异常导致的跨库事务。例如:同一事务中,跨两个库更新,更新完毕后、未提交之前,第一个库宕机,则只有第二个库数据提交。
因此使用两阶段事务来完全支持跨库事务。在sharding-jdbc中默认使用Atomikos,支持使用SPI的方式加载其他XA事务管理器。
不过,XA 并不是 Java 的技术规范(XA 提出那时还没有 Java),而是一套语言无关的通用规范,所以 Java 中专门定义了JSR 907 Java Transaction API,基于 XA 模式在 Java 语言中的实现了全局事务处理的标准,这也就是我们现在所熟知的 JTA。JTA 最主要的两个接口是:
- 事务管理器的接口:
javax.transaction.TransactionManager。这套接口是给 Java EE 服务器提供容器事务(由容器自动负责事务管理)使用的,还提供了另外一套javax.transaction.UserTransaction接口,用于通过程序代码手动开启、提交和回滚事务。 - 满足 XA 规范的资源定义接口:
javax.transaction.xa.XAResource,任何资源(JDBC、JMS 等等)如果想要支持 JTA,只要实现 XAResource 接口中的方法即可。
JTA 原本是 Java EE 中的技术,一般情况下应该由 JBoss、WebSphere、WebLogic 这些 Java EE 容器来提供支持,但现在Bittronix、Atomikos和JBossTM(以前叫 Arjuna)都以 JAR 包的形式实现了 JTA 的接口,称为 JOTM(Java Open Transaction Manager),使得我们能够在 Tomcat、Jetty 这样的 Java SE 环境下也能使用 JTA。
XA 将事务提交拆分成为两阶段过程:
- 准备阶段:又叫作投票阶段,在这一阶段,协调者询问事务的所有参与的是否准备好提交,参与者如果已经准备好提交则回复 Prepared,否则回复 Non-Prepared。这里所说的准备操作跟人类语言中通常理解的准备并不相同,对于数据库来说,准备操作是在重做日志中记录全部事务提交操作所要做的内容,它与本地事务中真正提交的区别只是暂不写入最后一条 Commit Record 而已,这意味着在做完数据持久化后并不立即释放隔离性,即仍继续持有锁,维持数据对其他非事务内观察者的隔离状态。
- 提交阶段:又叫作执行阶段,协调者如果在上一阶段收到所有事务参与者回复的 Prepared 消息,则先自己在本地持久化事务状态为 Commit,在此操作完成后向所有参与者发送 Commit 指令,所有参与者立即执行提交操作;否则,任意一个参与者回复了 Non-Prepared 消息,或任意一个参与者超时未回复,协调者将将自己的事务状态持久化为 Abort 之后,向所有参与者发送 Abort 指令,参与者立即执行回滚操作。对于数据库来说,这个阶段的提交操作应是很轻量的,仅仅是持久化一条 Commit Record 而已,通常能够快速完成,只有收到 Abort 指令时,才需要根据回滚日志清理已提交的数据,这可能是相对重负载操作。
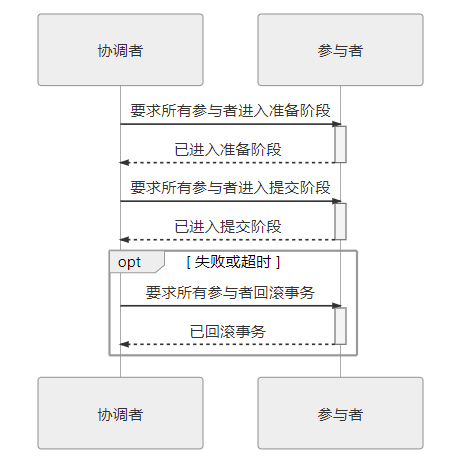
两段式提交原理简单,并不难实现,但有几个非常显著的缺点:
- 单点问题:协调者在两段提交中具有举足轻重的作用,协调者等待参与者回复时可以有超时机制,允许参与者宕机,但参与者等待协调者指令时无法做超时处理。一旦宕机的不是其中某个参与者,而是协调者的话,所有参与者都会受到影响。如果协调者一直没有恢复,没有正常发送 Commit 或者 Rollback 的指令,那所有参与者都必须一直等待。
- 性能问题:两段提交过程中,所有参与者相当于被绑定成为一个统一调度的整体,期间要经过两次远程服务调用,三次数据持久化(准备阶段写重做日志,协调者做状态持久化,提交阶段在日志写入 Commit Record),整个过程将持续到参与者集群中最慢的那一个处理操作结束为止,这决定了两段式提交的性能通常都较差。
- 一致性风险:前面已经提到,两段式提交的成立是有前提条件的,当网络稳定性和宕机恢复能力的假设不成立时,仍可能出现一致性问题。宕机恢复能力这一点不必多谈,1985 年 Fischer、Lynch、Paterson 提出了“FLP 不可能原理#Solvability_results_for_some_agreement_problems)”,证明了如果宕机最后不能恢复,那就不存在任何一种分布式协议可以正确地达成一致性结果。该原理在分布式中是与“CAP 不可兼得原理“齐名的理论。而网络稳定性带来的一致性风险是指:尽管提交阶段时间很短,但这仍是一段明确存在的危险期,如果协调者在发出准备指令后,根据收到各个参与者发回的信息确定事务状态是可以提交的,协调者会先持久化事物状态,并提交自己的事务,如果这时候网络忽然被断开,无法再通过网络向所有参与者发出 Commit 指令的话,就会导致部分数据(协调者的)已提交,但部分数据(参与者的)既未提交,也没有办法回滚,产生了数据不一致的问题。
排序、分页、函数计算问题
使用SQL时order by, limit关键字需要特殊处理,一般来说采用分片的思路
现在某个分片上执行相应的函数,然后将各个分片的结果集进行汇总和再次计算,最终得到结果。
分布式id
如果使用mysql可以在单库单表中使用id自增作为主键,分库分表就不行了,会出现id重复。
可以通过以下分布式id生成方案解决:
- UUID
- 基于数据库自增单独维护一张 ID表
- 号段模式
- Redis 缓存
- 雪花算法(Snowflake)
- 百度uid-generator
- 美团Leaf
- 滴滴Tinyid
本项目中,表插入操作在主库posys中进行,插入后会运行同步插件,实现新旧库的一致。
快速排序和归并排序的时间消耗对比
背景知识
快速排序和归并排序都基于递归的思想。其中归并排序每次将输入平均划分为两部分,因此时间复杂度为O(nlogn)。而快速排序根据选择的 pivot将其余的数据划分为大于s[pivot]和小于s[pivot]的,只有当s[pivot]恰好是中位数时,时间复杂度才是O(nlogn),最坏情况下, 每次选择的pivot都位于边缘,如下图所示。这样时间复杂度就退化为$O(n^2)$
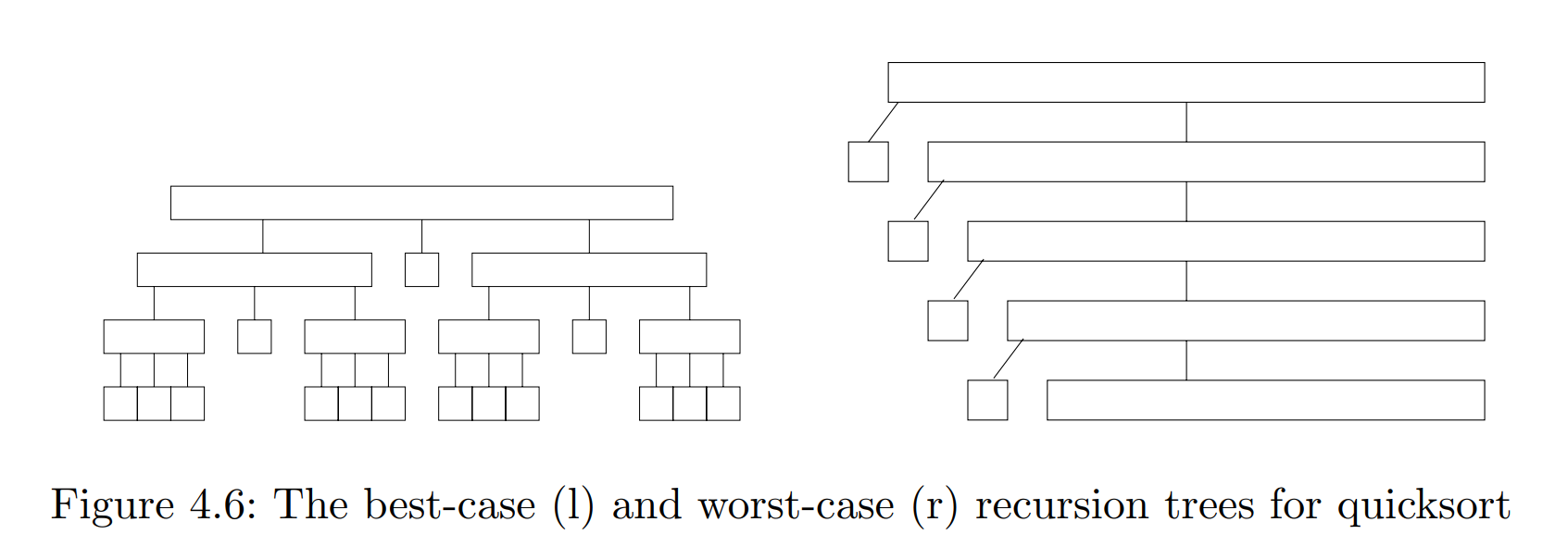
以上的分析是基于内存模型和大 O表示法的,而在实际运行过程中,由于归并排序归并需要的时间比快速排序时间长,因此时间的比较可能出现不一样的结果。本文将对其实际性能进行对比。本实验基于java 1.8。
实验结果
| 数组长度 | 初始化情况 | 快速排序 | 归并排序 | System |
|---|---|---|---|---|
| 1e6 | 有序 | StackOverflow | 496 | 5 |
| 1e6 | 无序 | 153 | 663 | 180 |
| 1e8 | 有序 | StackOverflow | 496 | 131 |
| 1e6 | 无序 | 17380 | too long | 17471 |
时间单位:ms
结果分析
可以看出,当数组是有序的时候,我们实现的快速排序算法性能会急剧下降,具体原因文章开头已经介绍了。对于这种情况,有以下几种解决方式:
排序之前对数组进行随机排列,时间复杂度为O(n)。
检查数组之前是否是有序的,在java Arrays.sort()中,如果数组长度超过286,且有序的子片段不超过67,则通过归并排序进行合并。
1 | public static <T> void sort(T[] a, Comparator<? super T> c) {} |
1 | public static void sort(int[] a) { |
核心代码
快速排序
1 | public class QuickSort { |
归并排序
1 | public class MergeSort { |
Android Studio中3个和构建相关的组件
android studio中3个和构建相关的组件
Gradle程序,这是和安卓独立的gradle系统,现在的版本号为6.5;
在项目中, gradle存储在gradle\wrapper\gradle-wrapper.properties文件中,以下载链接的方式存在。例如:

在构建中往往出现gradle下载不完全的问题,这时就会报错。打开
C:\Users\Administrator\.gradle\wrapper\dists文件夹,就能看到不同版本的gradle文件。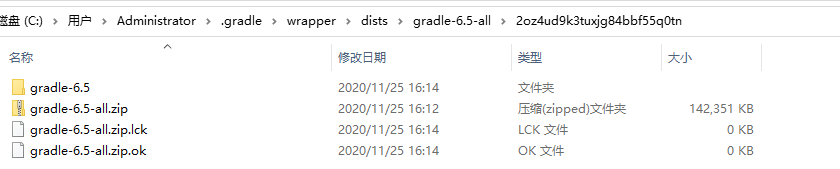
我们可以直接到
gradle-wrapper.properties指定的url下载压缩包并放到C:\Users\Administrator\.gradle\wrapper\dists\gradle-5.6.4-bin\bxirm19lnfz6nurbatndyydux类似的位置中。在启动构建时,android studio会自动解压并运行。android sdk build tools.这是安卓sdk中自带的构建工具。我们可以打开
 这个图标,选择SDK tools栏看到
这个图标,选择SDK tools栏看到
即已经安卓了相应的SDK build tools工具。在项目中的
 文件指定了需要的版本。
文件指定了需要的版本。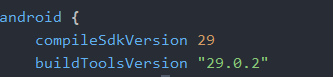 如这里是29.0.2。打开安卓sdk build-tools目录,如
如这里是29.0.2。打开安卓sdk build-tools目录,如C:\Users\Administrator\AppData\Local\Android\Sdk\build-tools就可以看到工具的所有版本。当出现下载问题时,可以到相应网站下载需要的工具版本,解压后重命名放到sdk build-tools目录中,android studio会自动检测并使用。gradle plugin. 除了以上两种,安卓还提供了一个构建插件。其版本号规定在项目文件
 中。即对于全局项目,使用的gradle插件是相同的。在打开android studio的时候,往往会提示我们更新gradle插件版本,其实就是指的它。一般情况下,gradle插件并不会导致太大的问题。
中。即对于全局项目,使用的gradle插件是相同的。在打开android studio的时候,往往会提示我们更新gradle插件版本,其实就是指的它。一般情况下,gradle插件并不会导致太大的问题。
gradle plugin 和 Gradle程序的兼容问题
下表列出了每个版本的Android Gradle插件所需的Gradle版本。 为了获得最佳性能,建议使用Gradle和插件的最新版本。
| Plugin version | Required Gradle version |
|---|---|
| 1.0.0 - 1.1.3 | 2.2.1 - 2.3 |
| 1.2.0 - 1.3.1 | 2.2.1 - 2.9 |
| 1.5.0 | 2.2.1 - 2.13 |
| 2.0.0 - 2.1.2 | 2.10 - 2.13 |
| 2.1.3 - 2.2.3 | 2.14.1+ |
| 2.3.0+ | 3.3+ |
| 3.0.0+ | 4.1+ |
| 3.1.0+ | 4.4+ |
| 3.2.0 - 3.2.1 | 4.6+ |
| 3.3.0 - 3.3.3 | 4.10.1+ |
| 3.4.0 - 3.4.3 | 5.1.1+ |
| 3.5.0 - 3.5.4 | 5.4.1+ |
| 3.6.0 - 3.6.4 | 5.6.4+ |
| 4.0.0+ | 6.1.1+ |
| 4.1.0+ | 6.5+ |
安卓程序的构建
文件结构

安卓项目主要分为三个级别:
- Project级别:项目包含的所有文件
- Module级别:例如app等模块,一个项目可以有多个模块。
- 代码模块,main文件夹下的所有文件。
build.gradle文件结构
主要包含两个文件:
全局构建配置文件build.gradle(Project)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28buildscript {
repositories {
jcenter()
maven {
url 'https://maven.google.com/'
name 'Google'
}
}
dependencies {
classpath 'com.android.tools.build:gradle:3.6.1'
// NOTE: Do not place your application dependencies here; they belong
// in the individual module build.gradle files
}
}
allprojects {
repositories {
jcenter()
maven {
url 'https://maven.google.com/'
name 'Google'
}
}
}
task clean(type: Delete) {
delete rootProject.buildDir
}位于根项目目录中的全局build.gradle文件定义了适用于项目中所有模块的构建配置。
默认情况下,buildscript块定义项目中所有模块通用的Gradle存储库和依赖项。
allprojects块用来配置存储库和所有模块共用的依赖,例如第三方插件和库,默认情况下,这里只包括jcenter和maven存储库。
dependencies配置了gradle构建项目需要的依赖,关于版本的问题前文已经提到过了。
模块配置文件 build.gradle(Module)
位于模块的根目录中,主要用于配置其所在的特定模块。我们可以通过配置这些构建设置来提供自定义打包选项,例如其他构建类型和产品类型,并覆盖manifest或全局build.gradle文件中的设置。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143/**
* The first line in the build configuration applies the Android plugin for
* Gradle to this build and makes the android block available to specify
* Android-specific build options.
*/
apply plugin: 'com.android.application'
/**
* The android block is where you configure all your Android-specific
* build options.
*/
android {
/**
* compileSdkVersion specifies the Android API level Gradle should use to
* compile your app. This means your app can use the API features included in
* this API level and lower.
*/
compileSdkVersion 28
/**
* buildToolsVersion specifies the version of the SDK build tools, command-line
* utilities, and compiler that Gradle should use to build your app. You need to
* download the build tools using the SDK Manager.
*
* This property is optional because the plugin uses a recommended version of
* the build tools by default.
*/
buildToolsVersion "29.0.2"
/**
* The defaultConfig block encapsulates default settings and entries for all
* build variants, and can override some attributes in main/AndroidManifest.xml
* dynamically from the build system. You can configure product flavors to override
* these values for different versions of your app.
*/
defaultConfig {
/**
* applicationId uniquely identifies the package for publishing.
* However, your source code should still reference the package name
* defined by the package attribute in the main/AndroidManifest.xml file.
*/
applicationId 'com.example.myapp'
// Defines the minimum API level required to run the app.
minSdkVersion 15
// Specifies the API level used to test the app.
targetSdkVersion 28
// Defines the version number of your app.
versionCode 1
// Defines a user-friendly version name for your app.
versionName "1.0"
}
/**
* The buildTypes block is where you can configure multiple build types.
* By default, the build system defines two build types: debug and release. The
* debug build type is not explicitly shown in the default build configuration,
* but it includes debugging tools and is signed with the debug key. The release
* build type applies Proguard settings and is not signed by default.
*/
buildTypes {
/**
* By default, Android Studio configures the release build type to enable code
* shrinking, using minifyEnabled, and specifies the default Proguard rules file.
*/
release {
minifyEnabled true // Enables code shrinking for the release build type.
proguardFiles getDefaultProguardFile('proguard-android.txt'), 'proguard-rules.pro'
}
}
/**
* The productFlavors block is where you can configure multiple product flavors.
* This allows you to create different versions of your app that can
* override the defaultConfig block with their own settings. Product flavors
* are optional, and the build system does not create them by default.
*
* This example creates a free and paid product flavor. Each product flavor
* then specifies its own application ID, so that they can exist on the Google
* Play Store, or an Android device, simultaneously.
*
* If you declare product flavors, you must also declare flavor dimensions
* and assign each flavor to a flavor dimension.
*/
flavorDimensions "tier"
productFlavors {
free {
dimension "tier"
applicationId 'com.example.myapp.free'
}
paid {
dimension "tier"
applicationId 'com.example.myapp.paid'
}
}
/**
* The splits block is where you can configure different APK builds that
* each contain only code and resources for a supported screen density or
* ABI. You'll also need to configure your build so that each APK has a
* different versionCode.
*/
splits {
// Settings to build multiple APKs based on screen density.
density {
// Enable or disable building multiple APKs.
enable false
// Exclude these densities when building multiple APKs.
exclude "ldpi", "tvdpi", "xxxhdpi", "400dpi", "560dpi"
}
}
}
/**
* The dependencies block in the module-level build configuration file
* specifies dependencies required to build only the module itself.
* To learn more, go to Add build dependencies.
*/
dependencies {
implementation project(":lib")
implementation 'com.android.support:appcompat-v7:28.0.0'
implementation fileTree(dir: 'libs', include: ['*.jar'])
}
参考文献
HuggingFace-Transformers系列的介绍以及在下游任务中的使用
内容介绍
这篇博客主要面向对Bert系列在Pytorch上应用感兴趣的同学,将涵盖的主要内容是:Bert系列有关的论文,Huggingface的实现,以及如何在不同下游任务中使用预训练模型。
看过这篇博客,你将了解:
- Transformers实现的介绍,不同的Tokenizer和Model如何使用。
- 如何利用HuggingFace的实现自定义你的模型,如果你想利用这个库实现自己的下游任务,而不想过多关注其实现细节的话,那么这篇文章将会成为很好的参考。
Huggingface-transformers介绍
transformers(以前称为pytorch-transformers和pytorch-pretrained-bert)提供用于自然语言理解(NLU)和自然语言生成(NLG)的BERT家族通用结构(BERT,GPT-2,RoBERTa,XLM,DistilBert,XLNet等),包含超过32种、涵盖100多种语言的预训练模型。同时提供TensorFlow 2.0和PyTorch之间的高互通性。
特性:
与pytorch-transformers一样易于使用
像Keras一样强大而简洁
在NLU和NLG任务上表现良好
对于教育者和从业者的门槛低
现存的模型:
Bert(基础版和巨人版, 是否区分大小写),
GPT, GPT-2
Transformer-XL, XLNet, XLM
DistilBERT, DistilGPT2
CTRL
ALBERT, RoBERTa, XLM-RoBERTa
FlauBERT,CamemBERT
- 其他在各种下游任务上微调过的模型。
- 在多语言上训练的模型
所需的知识
安装Huggface库(需要预先安装pytorch)
在阅读这篇文章之前,如果你能将以下资料读一遍,或者看一遍的话,在后续的阅读过程中将极大地减少你陷入疑惑的概率。
- 视频类内容:根据排序观看更佳
或者,你更愿意去看论文的话:
- 相关论文:根据排序阅读更佳
- BERT论文, BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, Authors: Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova
- Transformer-XL论文, Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context, Authors: Zihang Dai, Zhilin Yang, Yiming Yang, William W. Cohen, Jaime Carbonell, Quoc V. Le and Ruslan Salakhutdinov.
- XLNet论文,XLNet: Generalized Autoregressive Pretraining for Language Understanding
- ALBERT论文,ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
- RoBERTa论文, RoBERTa: A Robustly Optimized BERT Pretraining Approach
- DistilBERT论文,DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
HuggingFace模型加载+下游任务使用
项目组件
一个完整的transformer模型主要包含三部分:
Config,控制模型的名称、最终输出的样式、隐藏层宽度和深度、激活函数的类别等。将Config类导出时文件格式为 json格式,就像下面这样:
1
2
3
4
5
6
7
8
9
10
11
12
13{
"attention_probs_dropout_prob": 0.1,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"max_position_embeddings": 512,
"num_attention_heads": 12,
"num_hidden_layers": 12,
"type_vocab_size": 2,
"vocab_size": 30522
}当然,也可以通过config.json来实例化Config类,这是一个互逆的过程。
Tokenizer,这是一个将纯文本转换为编码的过程。注意,Tokenizer并不涉及将词转化为词向量的过程,仅仅是将纯文本分词,添加[MASK]标记、[SEP]、[CLS]标记,并转换为字典索引。Tokenizer类导出时将分为三个文件,也就是:
vocab.txt
词典文件,每一行为一个词或词的一部分
special_tokens_map.json 特殊标记的定义方式
1
2{"unk_token": "[UNK]", "sep_token": "[SEP]", "pad_token": "[PAD]",
"cls_token": "[CLS]", "mask_token": "[MASK]"}tokenizer_config.json 配置文件,主要存储特殊的配置。
Model,也就是各种各样的模型。除了初始的Bert、GPT等基本模型,针对下游任务,还定义了诸如
BertForQuestionAnswering等下游任务模型。模型导出时将生成config.json和pytorch_model.bin参数文件。前者就是1中的配置文件,这和我们的直觉相同,即config和model应该是紧密联系在一起的两个类。后者其实和torch.save()存储得到的文件是相同的,这是因为Model都直接或者间接继承了Pytorch的Module类。从这里可以看出,HuggingFace在实现时很好地尊重了Pytorch的原生API。
导入Bert系列基本模型的方法
通过官网自动导入
官方文档中初始教程提供的方法为:
1 | # from transformers import BertModel |
这个方法需要从官方的s3数据库下载模型配置、参数等信息(代码中已配置好位置)。这个方法虽然简单,但是在国内并不可用。当然你可以先尝试一下,不过会有很大的概率无法下载模型。
手动下载模型信息并导入
在HuggingFace官方模型库上找到需要下载的模型,点击模型链接, 这个例子使用的是bert-base-uncased模型
点击List all files in model,将其中的文件一一下载到同一目录中。例如,对于XLNet:
1
2
3
4
5
6# List of model files
config.json 782.0B
pytorch_model.bin 445.4MB
special_tokens_map.json 202.0B
spiece.model 779.3KB
tokenizer_config.json 2.0B但是这种方法有时也会不可用。如果您可以将Transformers预训练模型上传到迅雷等网盘的话,请在评论区告知,我会添加在此博客中,并为您添加博客友链。
通过下载好的路径导入模型:
1
2
3
4
5
6
7
8
9
10
11import transformers
MODEL_PATH = r"D:\transformr_files\bert-base-uncased/"
# a.通过词典导入分词器
tokenizer = transformers.BertTokenizer.from_pretrained(r"D:\transformr_files\bert-base-uncased\bert-base-uncased-vocab.txt")
# b. 导入配置文件
model_config = transformers.BertConfig.from_pretrained(MODEL_PATH)
# 修改配置
model_config.output_hidden_states = True
model_config.output_attentions = True
# 通过配置和路径导入模型
model = transformers.BertModel.from_pretrained(MODEL_PATH,config = model_config)
利用分词器分词
利用分词器进行编码
对于单句:
1
2
3# encode仅返回input_ids
tokenizer.encode("i like you")
Out : [101, 1045, 2066, 2017, 102]对于多句:
1
2
3
4
5
6# encode_plus返回所有编码信息
sen_code = tokenizer.encode_plus("i like you", "but not him")
Out :
{'input_ids': [101, 1045, 2066, 2017, 102, 2021, 2025, 2032, 102],
'token_type_ids': [0, 0, 0, 0, 0, 1, 1, 1, 1],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1]}
模型的所有分词器都是在PreTrainedTokenizer中实现的,分词的结果主要有以下内容:
1 | { |
编码解释:
- ‘input_ids’:顾名思义,是单词在词典中的编码
- ‘token_type_ids’, 区分两个句子的编码
- ‘attention_mask’, 指定对哪些词进行self-Attention操作
- ‘overflowing_tokens’, 当指定最大长度时,溢出的单词
- ‘num_truncated_tokens’, 溢出的token数量
- ‘return_special_tokens_mask’,如果添加特殊标记,则这是[0,1]的列表,其中0指定特殊添加的标记,而1指定序列标记
将input_ids转化回token
1 | tokenizer.convert_ids_to_tokens(sen_code['input_ids']) |
得到的结果是:
['[CLS]', 'i', 'like', 'you', '[SEP]', 'but', 'not', 'him', '[SEP]']
即tokenizer在编码时已经默认添加了标记。各模型对应的输入格式是这样的:
1 | bert: [CLS] + tokens + [SEP] + padding |
其中[CLS]对应分类等任务中的标记,[SEP]对应句子的结束,padding是当指定模型最大输入长度max_len时,需要补充的字符。
对编码进行转换,以便输入Tensor
1 | import torch |
将分词结果输入模型,得到编码
1 | # 将模型转化为eval模式 |
Bert最终输出的结果为:
1 | sequence_output, pooled_output, (hidden_states), (attentions) |
以输入序列长度为14为例
| index | 名称 | 维度 | 描述 |
|---|---|---|---|
| 0 | sequence_output | torch.Size([1, 14, 768]) | 输出序列 |
| 1 | pooled_output | torch.Size([1, 768]) | 对输出序列进行pool操作的结果 |
| 2 | (hidden_states) | tuple,13*torch.Size([1, 14, 768]) | 隐藏层状态(包括Embedding层),取决于modelconfig中output_hidden_states |
| 3 | (attentions) | tuple,12*torch.Size([1, 12, 14, 14]) | 注意力层,取决于参数中output_attentions |
Bert总结
这一节我们以Bert为例对模型整体的流程进行了了解。之后的很多模型都基于Bert,并基于Bert进行了少量的调整。其中的输出和输出参数也有很多重复的地方。
利用预训练模型在下游任务上微调
如开头所说,这篇文章重点在于”如何进行模型的调整以及输入输出的设定”, 以及”Transformer的实现进行简要的提及”, 所以,我们不会去介绍、涉及如何写train循环等话题,而仅仅专注于模型。也就是说,我们将止步于跑通一个模型,而不计批量数据预处理、训练、验证等过程。
同时,这里更看重如何基于Bert等初始模型在实际任务上进行微调,所以我们不会仅仅地导入已经在下游任务上训练好的模型参数,因为在这些模型上使用的方法和上一章的几乎完全相同。
这里的输入和输入以模型的预测过程为例。
问答任务 via Bert
任务输入:问题句,答案所在的文章 "Who was Jim Henson?", "Jim Henson was a nice puppet"
任务输出:答案 "a nice puppet"
现存的模型输入输出和任务的输入输出有一定差别,这也是在使用上需要区别的地方:
模型输入:inputids, token_type_ids
模型输出:start_scores, end_scores 形状都为torch.Size([1, 14]),其中14为序列长度,代表每个位置是开始/结束位置的概率。
模型的构建:
一般情况下,一个基本模型对应一个Tokenizer, 所以并不存在对应于具体下游任务的Tokenizer。这里通过bert_model初始化BertForQuestionAnswering。
1 | from transformers import BertTokenizer, BertForQuestionAnswering |
利用模型进行运算:
1 | # 设定模式 |
将模型输出转化为任务输出:
1 | # 对输出的答案进行解码的过程 |
文本分类任务(情感分析等) via XLNet
任务输入:句子 "i like you, what about you"
任务输出:句子所属的类别 class1
模型输入:inputids, token_type_ids
模型输出:logits, hidden states, 其中logits形状为torch.Size([1, 3]), 其中的3对应的是类别的数量。当训练时,第一项为loss。
模型的构建:
1 | from transformers import XLNetConfig, XLNetModel, XLNetTokenizer, XLNetForSequenceClassification |
利用模型进行运算:
1 | # 设定模式 |
输出的转化可直接通过numpy的argmax函数实现。
其他的任务,将继续更新
其他的模型和之前的两个大致是相同的,你可以自己发挥。我会继续在相关的库上进行实验,如果发现用法不一样的情况,将会添加在这里。
参考
本文章主要对HuggingFace库进行了简要介绍。具体安装等过程请参见官方github仓库。
本文主要参考于官方文档
同时,在模型的理解过程中参考了一些kaggle上的notebooks, 主要是这一篇,作者是Abhishek Thakur
修改记录
- 2020/5/4
- 添加不同模型需要的分词格式变化
- 增改论文链接
解决Mysql无法远程连接的问题
前言
最近开发中遇到一个问题,mysql在服务器本地可以登录,但是远程通过3306端口却不可以。这个问题困扰了我一周之久,终于在今天解决了。在解决的过程中试了很多的方法,遂记录下来,希望能给大家一些提示。
排查错误位置
客户端方面
首先通过ping命令对服务器进行测试,如果ping不通,则是网络的问题,本文中没有涉及这类问题的解决。
如果能ping通,再测试端口有没有问题。首先安装telnet, telnet是windows系统自带的,搜索”启动或关闭Windows功能”, 找telnet客户端,勾选即可启动。在cmd中输入telnet {服务器IP} 3306, 如果不能正确连接,说明是端口设置的问题, 再试试22端口有没有问题,如果也有问题,就是服务器整体的端口设置有问题,如果只有3306有问题,那么就是3306端口、mysql的设置问题,继续往下测试。
服务器方面
针对只有3306端口不能连接的情况,有以下几种解决方法:
1. 修改配置文件,开启对其他ip地址的监听
输入命令netstat -ntpl |grep 3306 和 netstat -ntpl |grep 22, 查看端口的绑定情况
正确情况下应为以下输出:
如果3306只绑定的本地端口,就会出现和上图不一致的输出。需要对其配置文件进行修改:
1 | sudo nano /etc/mysql/mysql.conf.d/mysqld.cnf |
打开配置文件, 找到bind-address开头的一行,如果后面的ip地址是127.0.0.1,也就是服务器只会接收本地的连接请求,那么就需要改变此地址来指向外部的IP地址。例如,可以改为:1
2
3
4
5
6lc-messages-dir = /usr/share/mysql
skip-external-locking
Instead of skip-networking the default is now to listen only on
localhost which is more compatible and is not less secure.
bind-address = 0.0.0.0
如果你的mysql版本是MySQL 8+,那么mysqld.cnf中可能不会包含bind-address这一行,应该像下面所示方法进行添加:1
2
3
4
5
6[mysqld]
pid-file = /var/run/mysqld/mysqld.pid
socket = /var/run/mysqld/mysqld.sock
datadir = /var/lib/mysql
log-error = /var/log/mysql/error.log
bind-address = 0.0.0.0
修改完成后,保存并退出。重启mysql服务sudo systemctl restart mysql,使得配置文件的修改得以生效。
接下来再次回到客户端进行验证,如果能够telnet连接3306端口,说明配置成功,如果还是不能连接,进入下一步骤。
2. 关闭防火墙
Ubuntu默认的防火墙为ufw。防火墙的作用是管理网络规则,默认情况下打开防火墙是更好的选择, 但是这里为了排除debug时的影响,就先关闭一下。
查看防火墙状态sudo ufw status, 如果显示active, 就运行sudo ufw disable关闭。
3. 修改 iptables
iptables定义了网络访问规则,它工作在内核中,是一个网络过滤器。
运行1
sudo iptables -I INPUT -p tcp --dport 3306 -j ACCEPT
表示添加接收3306端口的规则。
-I INPUT将当前命令插入在filter链的第一位置。
-p tcp表示添加tcp协议的扩展。
—dport XX-XX:指定目标端口。
-j ACCEPT: 规定的动作,这里为接收。
完成后,保存修改的配置sudo iptables-save。
然后再次在客户端用telnet进行测试,得到结果:
说明连接3306端口成功了。(忽略这里的乱码)
软件性能测试的标准
性能测试标准及其定义
事务:从客户端发起一个或多个请求(这些请求组成一个完整的操作),到客户端接收到从服务器返回的响应。
TPS: Transaction Per Second,每秒钟系统能够处理的事务数
请求响应事件:从客户端发起的一个请求开始,到客户端接收到从服务器返回的响应,整个过程耗费的时间。
事务响应时间:事务可能是由一个或多个请求组成的,事务响应时间主要是针对与用户的角度而言,如转账。
并发的定义:没有严格意义上的并发。并发总有先后,所以并发讲的是一个时间范围内,比如1秒。
并发用户数:同一单位时间内,对系统发起请求的用户数量
吞吐量:一次性能测试过程中网络上传输的数据量的总和。
吞吐率:单位时间内网络上传输的数据量。
吞吐率 = 吞吐量/传输时间
点击率:每秒钟用户向服务器提交的请求数,是 web应用程序的特有指标。一次单击操作后,客户端有可能向服务器发送了多个请求。
资源使用率:对不同的系统资源的使用情况,如cpu、内存、io。
Jmeter的构成
测试计划
线程组:多个线程,模拟多用户并发
监听器:调试脚本,对一些资源进行监控
配置元件:做一些配置,如http头,mysql连接信息。
后置处理器:并发完成之后做一些事情。
前置处理器:请求发生之前要做一些什么。
逻辑控制器
Sampler:放所有的请求
逻辑控制器和Sampler都是基于线程之下进行工作的。
Android屏幕绘制原理
Java需要记住的几件事儿
继承篇
新建对象时,引用必须比new对象的等级高
- 新建对象时,包含两部分,一部分是new出来的对象,一部分是创建的新引用。引用的类型可以是接口、抽象类、普通类,而new对象的类型必须是实现类,这个实现类常见的有三种表现形式,一种是普通的类,另外是抽象类或接口,但是必须实现所有还没有实现的方法。引用的类型可以使用new出来对象的父类,但是不能使用其子类。可以这样理解:引用的作用是调用方法,子类往往拥有比父类更多的方法(通过继承多个接口等),因此只能用方法更少的父类指向方法更多的子类,以防我们引用了某个方法,但是在new出来的对象中并不存在,造成错误。
cast对象时,需要从子类cast为父类 需要从内存中实际对象的类别转化为其父类或本身
- 和上面的一条有异曲同工之妙,在类型强转之后,我们需要调用对象中的方法,强转的过程想必也不会添加新的方法吧。所以强转是不是可以看作是单纯地去掉一些方法呢,其实不是的。强转的最大作用其实是让我们用不同的引用类型去访问同一个对象,而堆中的对象本身并没有改变。
- 但是,在安卓开发中经常会用到 (Button) findViewById(R.id.activity_button) 这样的操作,而Button明明是子类啊,为什么可以强转呢?区别在于引用指向的对象在内存中究竟是什么。如果其在内存中是以Button存在的,那么即使返回类型是以View引用的,也可以强转回Button。
子类override父类的方法时,可以改变方法的返回值,但是返回值必须是父类返回值的子类
- 还是和引用与实现对象的类型有关。在调用方法时,利用的是引用的类型,即父类。如果引用类型中没有某个方法,就无法调用,即使实现对象中有此方法。所以父类方法的返回类型就是我们调用方法时期望得到的类型。我们可能会利用一个返回值引用去指向得到的返回值。所以由“新建对象时,引用必须比new对象的等级高”可知,返回值引用的类型要比返回对象的等级高,如果子类实现返回一个等级更高的对象,就可能违背这个原则。
方法中实际返回的类型要比声明的类型等级低
- 由原则1,2易得
运行篇
守护线程和用户线程
在java程序开始执行之后,会产生多个线程。主要分为用户线程和守护线程。用户线程包括我们平时使用的main函数创建的主线程,这个线程主要完成一些复杂的工作,而守护线程则是为了程序正常运行提供服务的线程。他们主要有以下区别:
jvm只等待用户线程结束才结束
用户线程优先级比守护线程高
这保证了cpu会优先满足用户进程的执行
由谁创建:用户线程通常由用户创建,而守护线程往往由操作系统创建
用户线程是jvm运行的前提,当只有守护线程时,jvm无法继续运行
栈帧的组成
Each frame contains:
Local variable array 本地变量数组
- boolean
- byte
- char
- long
- short
- int
- float
- double
- reference
- returnAddress
除了double和float之外,都占用8个字节/32bit
Return value 返回值
Operand stack 操作数栈
Reference to runtime constant pool for class of the current method 运行时常量池的引用
运行时常量池的作用
在c(++)语言中,代码通常被编译为一个个对象,然后通过连接他们来产生可运行文件或者dll。在连接阶段,符号引用被实际的内存地址代替。而在java中这个过程是在运行时动态实现的。
当java class被加载到jvm中之后,所有的引用和变量都会被存储在类的常量池中,这里的存储使用的是符号引用,而不是对应于实际的地址引用。jvm的具体实现可以选择何时解析符号引用,分为两种,饥饿模式和懒汉模式。饥饿模式的解析发生在字节码验证之后,懒汉模式则发生在引用和变量第一次被使用时。Binding是变量、方法的符号引用被直接引用取代的过程,这个过程只发生一次。