概括
这篇文章将对Bert等模型使用的分词技术进行介绍。同时会涉及这些分词器在huggingface tokenizers库中的使用。理解这些分词器的原理,对于灵活使用transformers库中的不同模型非常重要。除此之外,我们还能将这些分词器用于其他任务中,如果有必要的话,我们还能自己训练分词器。
分词器是做什么的?
机器无法理解文本。当我们将句子序列送入模型时,模型仅仅能看到一串字节,它无法知道一个词从哪里开始,到哪里结束,所以也不知道一个词是怎么组成的。
所以,为了帮助机器理解文本,我们需要
- 将文本分成一个个小片段
- 然后将这些片段表示为一个向量作为模型的输入
- 同时,我们需要将一个个小片段(token) 表示为向量,作为词嵌入矩阵, 通过在语料库上训练来优化token的表示,使其蕴含更多有用的信息,用于之后的任务。
古典分词方法
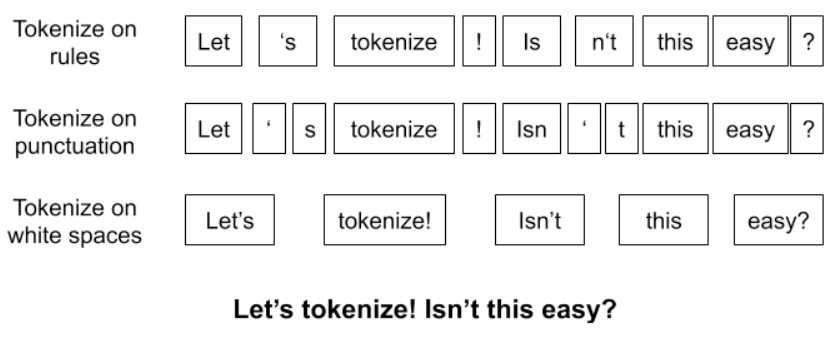
基于空格的分词方法
一个句子,使用不同的规则,将有许多种不同的分词结果。我们之前常用的分词方法将空格作为分词的边界。也就是图中的第三种方法。但是,这种方法存在问题,即只有在训练语料中出现的token才能被训练器学习到,而那些没有出现的token将会被<UNK>等特殊标记代替,这样将影响模型的表现。如果我们将词典做得足够大,使其能容纳所有的单词。那么词典将非常庞大,产生很大的开销。同时对于出现次数很少的词,学习其token的向量表示也非常困难。除去这些原因,有很多语言不用空格进行分词,也就无法使用基于空格分词的方法。综上,我们需要新的分词方法来解决这些问题。
基于字母的分词方法
简单来说,就是将每个字符看作一个词。
优点: 不用担心未知词汇,可以为每一个单词生成词嵌入向量表示。
缺点:
- 字母本身就没有任何的内在含义,得到的词嵌入向量缺乏含义。
- 计算复杂度提升(字母的数目远大于token的数目)
- 输出序列的长度将变大,对于Bert、CNN等限制最大长度的模型将很容易达到最大值。
基于子词的分词方法(Subword Tokenization)
为了改进分词方法,在<UNK>数目和词向量含义丰富性之间达到平衡,提出了Subword Tokenization方法。这种方法的目的是通过一个有限的单词列表来解决所有单词的分词问题,同时将结果中token的数目降到最低。例如,可以用更小的词片段来组成更大的词:
“unfortunately” = “un” + “for” + “tun” + “ate” + “ly”。
接下来,将介绍几种不同的Subword Tokenization方法。
Byte Pair Encoding (BPE) 字节对编码
概述
字节对编码最早是在信号压缩领域提出的,后来被应用于分词任务中。在信号压缩领域中BPE过程可视化如下:

接下来重点介绍将BPE应用于分词任务的流程:
实现流程
- 根据语料库建立一个词典,词典中仅包含单个字符,如英文中就是a-z
- 统计语料库中出现次数最多的字符对(词典中两项的组合),然后将字符对加入到词典中
- 重复步骤2直到到达规定的步骤数目或者词典尺寸缩小到了指定的值。
BPE的优点
可以很有效地平衡词典尺寸和编码步骤数(将句子编码所需要的token数量)
BPE存在的缺点:
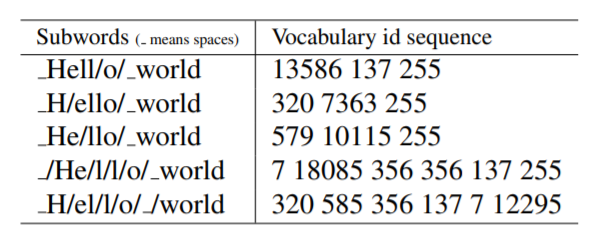
- 对于同一个句子, 例如Hello world,如图所示,可能会有不同的Subword序列。不同的Subword序列会产生完全不同的id序列表示,这种歧义可能在解码阶段无法解决。在翻译任务中,不同的id序列可能翻译出不同的句子,这显然是错误的。
- 在训练任务中,如果能对不同的Subword进行训练的话,将增加模型的健壮性,能够容忍更多的噪声,而BPE的贪心算法无法对随机分布进行学习。
Unigram Based Tokenization
方法概述
分词中的Unigram模型是Kudo.在论文“Subword Regularization: Improving Neural Network Translation Models with Multiple Subword Candidates”中提出的。当时主要是为了解决机器翻译中分词的问题。作者使用一种叫做marginalized likelihood的方法来建模翻译问题,考虑到不同分词结果对最终翻译结果的影响,引入了分词概率$P(\vec{x}|X)$来表示$X$最终分词为$\vec{x}$的概率(X为原始的句子, $\vec{x}$为分词的结果$\vec{x} = (x_1, . . . , x_M) $,由多个subword组成)。传统的BPE算法无法对这个概率进行建模,因此作者使用了Unigram语言模型来达到这样的目的。
方法执行过程
假设:根据unigram的假设,每个字词的出现是独立的。所以
这里的$x_i$是从预先定义好的词典$V$中取得的,所以,最有可能的分词方式就可以这样表示:
这里$S(X)$是句子$X$不同的分词结果集合。$x^*$可以通过维特比算法得到。
如果已知词典$V$, 我们可以通过EM算法来估计$p(x_i)$,其中M步最大化的对象是以下似然函数(原谅我这里偷懒直接使用图片):
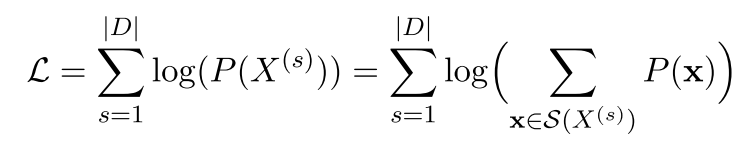
$|D|$是语料库中语料数量。
我是这样理解这个似然函数的:将语料库中所有句子的所有分词组合形成的概率相加。
初始时,我们连词典$V$都没有,作者通过不断执行以下步骤来构造合适的词典以及分词概率:
从头构建一个相当大的种子词典。
重复以下步骤,知道字典尺寸$|V|$减小到期望值:
固定词典,通过EM算法优化$p(x)$
为每一个子词计算$loss_i$,loss代表如果将某个词去掉,上述似然函数值会减少多少。根据loss排序,保留loss最高的$\eta$个子词。注意:保留所有的单字符,从而避免OOV情况。
我是这样理解loss的:若某个子词经常以很高的频率出现在很多句子的分词结果中,那么其损失将会很大,所以要保留这样的子词。
主要贡献:
- 使用的训练算法可以利用所有可能的分词结果,这是通过data sampling算法实现的。
- 提出一种基于语言模型的分词算法,这种语言模型可以给多种分词结果赋予概率,从而可以学得其中的噪声。
将基于子词的分词方法应用到实际中
Bert中的WordPiece分词器
WordPiece是随着Bert论文的出现被提出的。在整体步骤上,WordPiece方法和BPE是相同的。即也是自低向上地构建词典。区别是BPE在每次合并的时候都选择出现次数最高的字符对,而WordPiece使用的是类似于Unigram的方法,即通过语言模型来得到合并两个单词可能造成的影响,然后选择使得似然函数提升最大的字符对。这个提升是通过结合后的字符对减去结合前的字符对之和得到的。也就是说,判断“de”相较于“d”+”e”是否更适合出现。
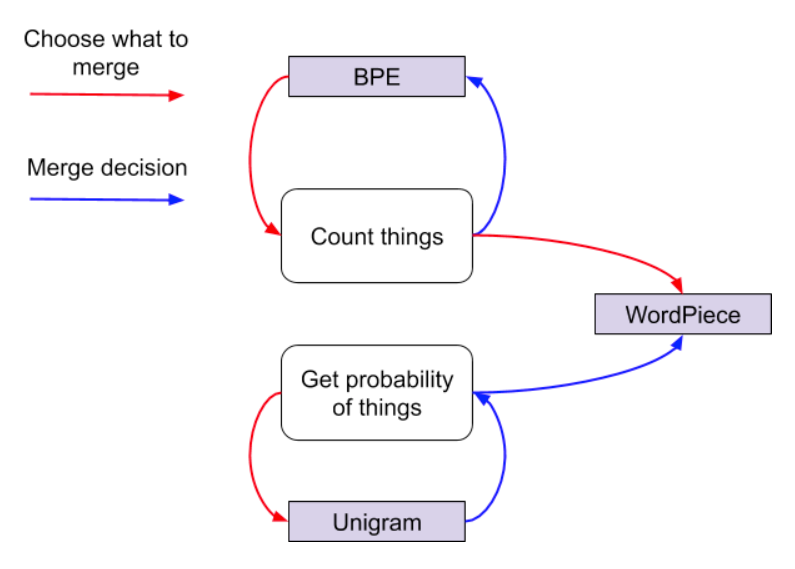
三种分词器的关系如下:(图自FloudHub Blog)
SentencePiece库
SentencePiece是在“SentencePiece: A simple and language independent subword tokenizer
and detokenizer for Neural Text Processing”这篇文章中介绍的。其主要是为了解决不同语言分词规则需要特别定义的问题,比如下面这种情况:
1 | Raw text: Hello world. |
将分词结果解码到原来的句子中时,会在不同的词之间添加空格,生成Decoded text所示的结果,这就是编码解码出现的歧义性,因此需要特别定义规则来实现互逆。还有一个例子是,在解码阶段,欧洲语言词之间要添加空格,而中文等语言则不应添加空格。对于这种区别,也需要单独定制规则,这些繁杂的规则维护起来非常困难,所以作者采用以下的方案来解决:
1 | 将所有的字符都转化成Unicode编码,空格用‘_’来代替,然后进行分词操作。这样空格也不需要特别定义规则了。然后在解码结束后,使用Python代码恢复即可: |
SentencePiece库主要由以下部分组成:
“Normalizer, Trainer, Encoder, Decoder”
其中Normalizer用来对Unicode编码进行规范化,这里使用的算法是NFKC方法,同时也支持自定义规范化方法。Trainer则用来训练分词模型。Encoder是将句子变成编码,而Decoder是反向操作。他们之间存在以下函数关系:
Huggingface tokenizers库的介绍和使用
tokenizers是集合了当前最常用的分词器集合,效率和易用性也是其关注的范畴。
使用示例:
1 | # Tokenizers provides ultra-fast implementations of most current tokenizers: |
自己训练分词器
1 | # You can also train a BPE/Byte-levelBPE/WordPiece vocabulary on your own files |
参考材料
这篇文章是在Floydhub的一篇博客基础上扩展的。还主要参考了Unigram的原论文,BPE的官方解释等。BPE的动态图来自于Toward data science的有关博客。除此之外,最后一章参考于tokenizers的官方仓库。